入门概念
Spark是什么
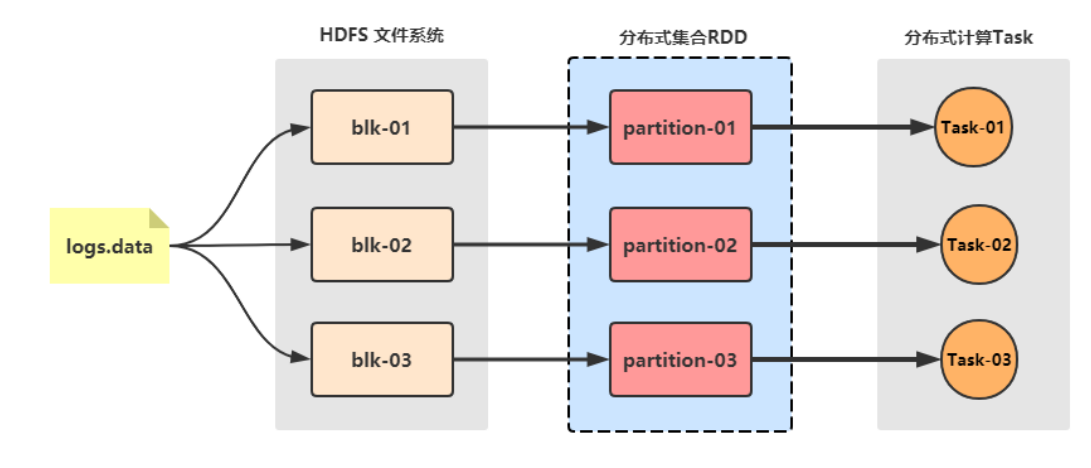
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。Spark 最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念。翻译过来就是:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。
Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
统一搜索引擎
Spark是一款分布式内存计算的统一分析引擎。其特点就是对任意类型的数据进行自定义计算。Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用程序计算数据。Spark的适用面非常广泛,所以,被称之为 统一的(适用面广)的分析引擎(数据处理)
与Hadoop的区别
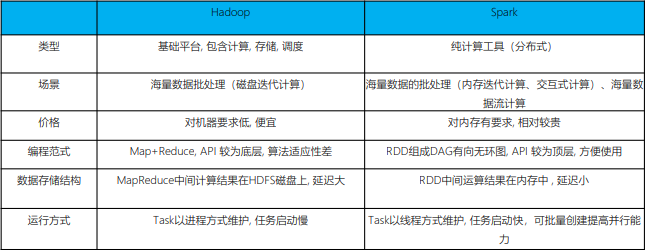
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop:
- 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive
- Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
Hadoop的基于进程的计算和Spark基于线程方式优缺点
Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
四大特点
速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- Spark处理数据时,可以将中间处理结果数据存储到内存中;
- Spark 提供了非常丰富的算子(API), 可以做到复杂任务在一个Spark 程序中完成.
易于使用
Spark 的版本已经更新到 Spark 3.2.0(截止日期2021.10.13),支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言。为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本
通用性强
在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。
运行方式
Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark2.3开始支持)上。
对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
Spark 框架模块
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上
Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
Spark的运行模式
Spark提供多种运行模式,包括:
- 本地模式(单机)
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境 - Standalone模式(集群)
Spark中的各个角色以独立进程的形式存在,并组成Spark集群环境 - Hadoop YARN模式(集群)
Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境 - Kubernetes模式(容器集群)
Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境 - 云服务模式(运行在云平台上)...
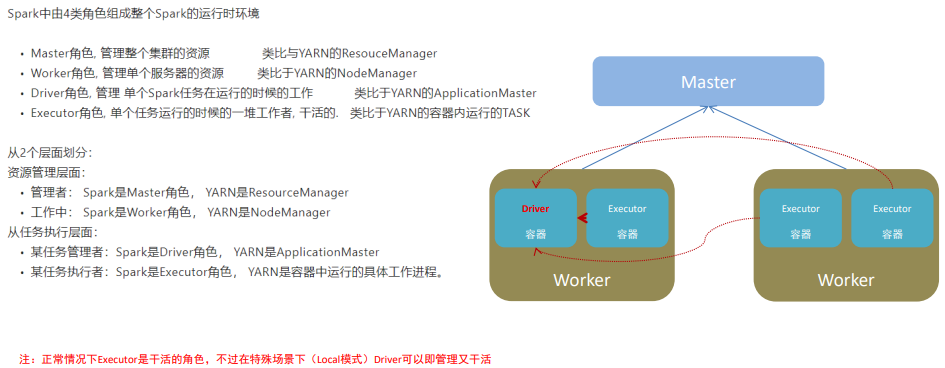
Spark的架构角色
YARN运行角色
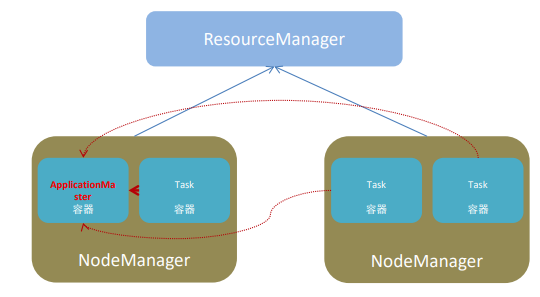
YARN主要有4类角色,从2个层面去看:
资源管理层面
集群资源管理者(Master):ResourceManager
单机资源管理者(Worker):NodeManager任务计算层面
单任务管理者(Master):ApplicationMaster
单任务执行者(Worker):Task(容器内计算框架的工作角色)
Spark运行角色
LOCAL模式
Local模式可以限制模拟Spark集群环境的线程数量, 即Local[N] 或 Local[*],其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程(该线程有1个core)。 通常Cpu有几个Core,就指定几个线程,最大化利用计算能力。如果是local[*],则代表 Run Spark locally with as many worker threads aslogical cores on your machine。按照Cpu最多的Cores设置线程数。
LOCAL模式本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务TaskLocal模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境. (通过多线程来模拟集群环境)
Local模式可以通过spark-shell/pyspark/spark-submit等来开启
角色分布
资源管理:
Master:Local进程本身
Worker:Local进程本身
任务执行:
Driver:Local进程本身
Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力
Driver也算一种特殊的Executor, 只不过多数时候, 我们将Executor当做纯Worker对待, 这样和Driver好区分(一类是管理,一类是工人)。 Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行。
Standalone模式
Standalone 架构
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个线程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
StandAlone 是完整的Spark运行环境,其中:
Master角色以Master进程存在, Worker角色以Worker进程存在
Driver和Executor运行于Worker进程内, 由Worker提供资源供给它们运行
StandAlone集群的三类进程
StandAlone集群在进程上主要有3类进程:
主节点Master进程:
Master角色, 管理整个集群资源,并托管运行各个任务的Driver
从节点Workers:
Worker角色, 管理每个机器的资源,分配对应的资源来运行Executor(Task);每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
历史服务器HistoryServer(可选):
Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。

Application在集群上的组成部分
Spark Application运行到集群上时,由两部分组成:Driver Program和Executors。
第一、Driver Program
相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;
运行JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;
一个SparkApplication仅有一个;
第二、Executors
相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,一个Task任务运行需要1 Core CPU,所有可以认为Executor中线程数就等于CPU Core核数;
一个Spark Application可以有多个,可以设置个数和资源信息;
运行阶段的划分
用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
1)、用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 Cluster Manager 会根据用户提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor。
2)、Driver会将用户程序划分为不同的执行阶段Stage,每个执行阶段Stage由一组完全相同Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后, Driver会向Executor发送 Task;
3)、Executor在接收到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态汇报给Driver;
4)、Driver会根据收到的Task的运行状态来处理不同的状态更新。 Task分为两种:一种是Shuffle Map Task,它实现数据的重新洗牌,洗牌的结果保存到Executor 所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据;
5)、Driver 会不断地调用Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成功时停止;
web端口
4040: 是一个运行的Application在运行的过程中临时绑定的端口,用以查看当前任务的状态.4040被占用会顺延到4041.4042等,4040是一个临时端口,当前程序运行完成后, 4040就会被注销。
8080: 默认是StandAlone下, Master角色(进程)的WEB端口,用以查看当前Master(集群)的状态
18080: 默认是历史服务器的端口, 由于每个程序运行完成后,4040端口就被注销了. 在以后想回看某个程序的运行状态就可以通过历史服务器查看,历史服务器长期稳定运行,可供随时查看被记录的程序的运行过程
运行顺序
在一个Spark Application中,包含多个Job,每个Job有多个Stage组成,每个Job执行按照DAG图进行的。
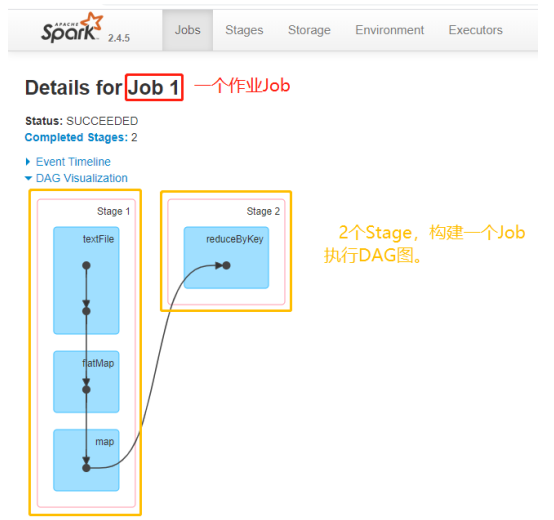
Spark Application程序运行时三个核心概念:Job、Stage、Task,说明如下:
Job:由多个 Task 的并行计算部分,一般 Spark 中的action 操作(如 save、collect,后面进一步说明),会生成一个 Job。
Stage:Job 的组成单位,一个 Job 会切分成多个 Stage,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多个 Task 的集合,类似 map 和 reduce stage。
Task:被分配到各个 Executor 的单位工作内容,它是Spark 中的最小执行单位,一般来说有多少个 Paritition(物理层面 的概念,即分支可以理解为将数据划分成不同部分并行处理),就会有多少个 Task,每个 Task 只会处理单一分支 上的数据。
StandAlone HA
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。
高可用HA
如何解决这个单点故障的问题,Spark提供了两种方案:
-
基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
-
基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境
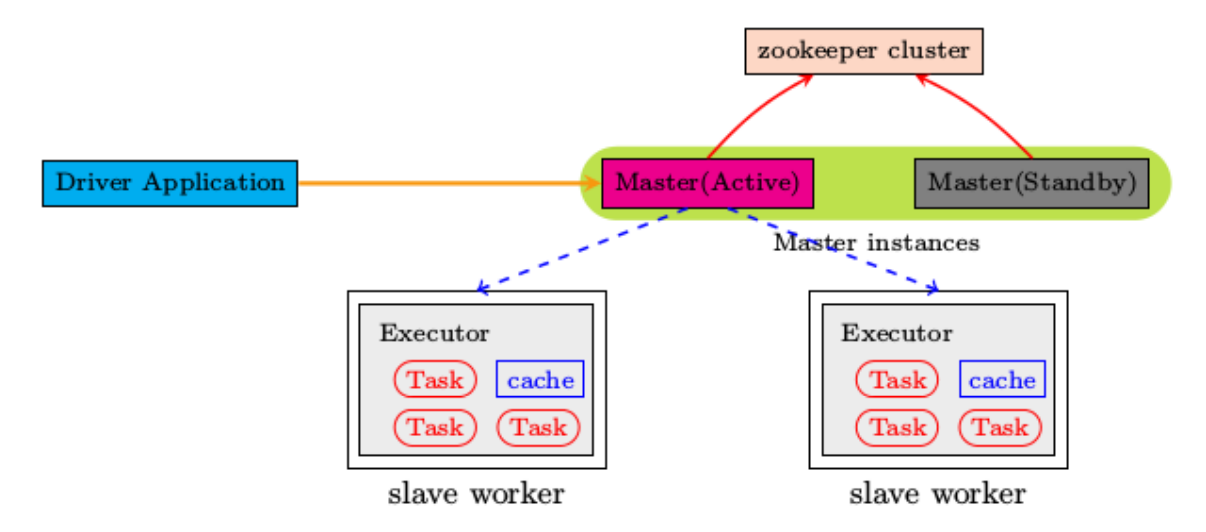
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
SparkOnYarn
按照前面环境部署中所学习的, 如果我们想要一个稳定的生产Spark环境, 那么最优的选择就是构建:HA StandAlone集群。不过在企业中, 服务器的资源总是紧张的, 许多企业不管做什么业务,都基本上会有Hadoop集群. 也就是会有YARN集群。
对于企业来说,在已有YARN集群的前提下在单独准备Spark StandAlone集群,对资源的利用就不高. 所以, 在企业中,多
数场景下,会将Spark运行到YARN集群中。YARN本身是一个资源调度框架, 负责对运行在内部的计算框架进行资源调度管理.。作为典型的计算框架, Spark本身也是直接运行在YARN中, 并接受YARN的调度的。所以, 对于Spark On YARN, 无需部署Spark集群, 只要找一台服务器, 充当Spark的客户端, 即可提交任务到YARN集群中运行。
SparkOnYarn本质
Master角色由YARN的ResourceManager担任.
Worker角色由YARN的NodeManager担任.
Driver角色运行在YARN容器内 或 提交任务的客户端进程中
真正干活的Executor运行在YARN提供的容器内
部署模式
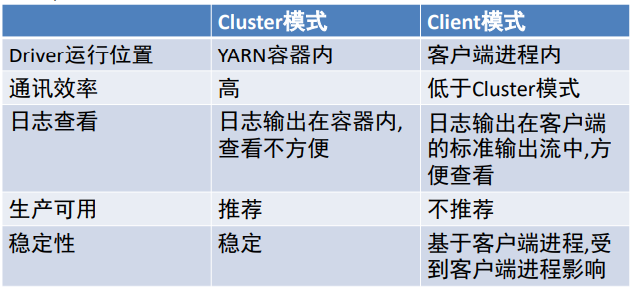
Spark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式.这两种模式的区别就是Driver运行的位置。
Cluster模式即:Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内;
Client模式即:Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中。
# client部署模式
bin/spark-submit --master yarn --deploy-mode client
# cluster部署模式
bin/spark-submit --master yarn --deploy-mode cluster
# 其他参数
--driver-memory 512m #控制driver内存
--executor-memory 512m #控制executor内存
--num-executors 3 #控制executor数量
--total-executor-cores 3 #控制executor总共可使用集群核心数运行流程
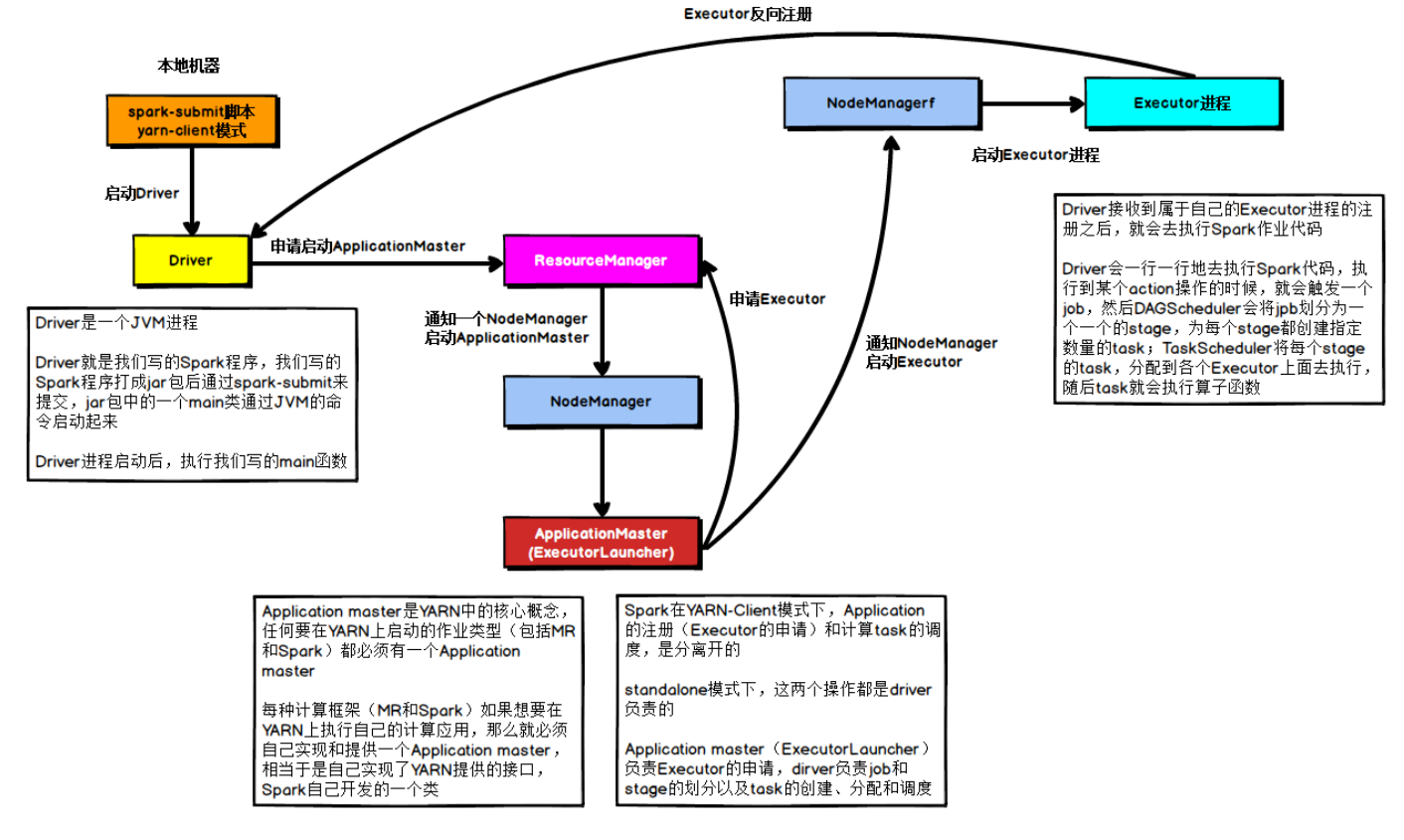
在YARN Client模式下,Driver在任务提交的本地机器上运行,示意图如下:
具体流程步骤如下:
1)、Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
3)、ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
5)、之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
在YARN Cluster模式下,Driver运行在NodeManager Contanier中,此时Driver与AppMaster合为一体,示意图如
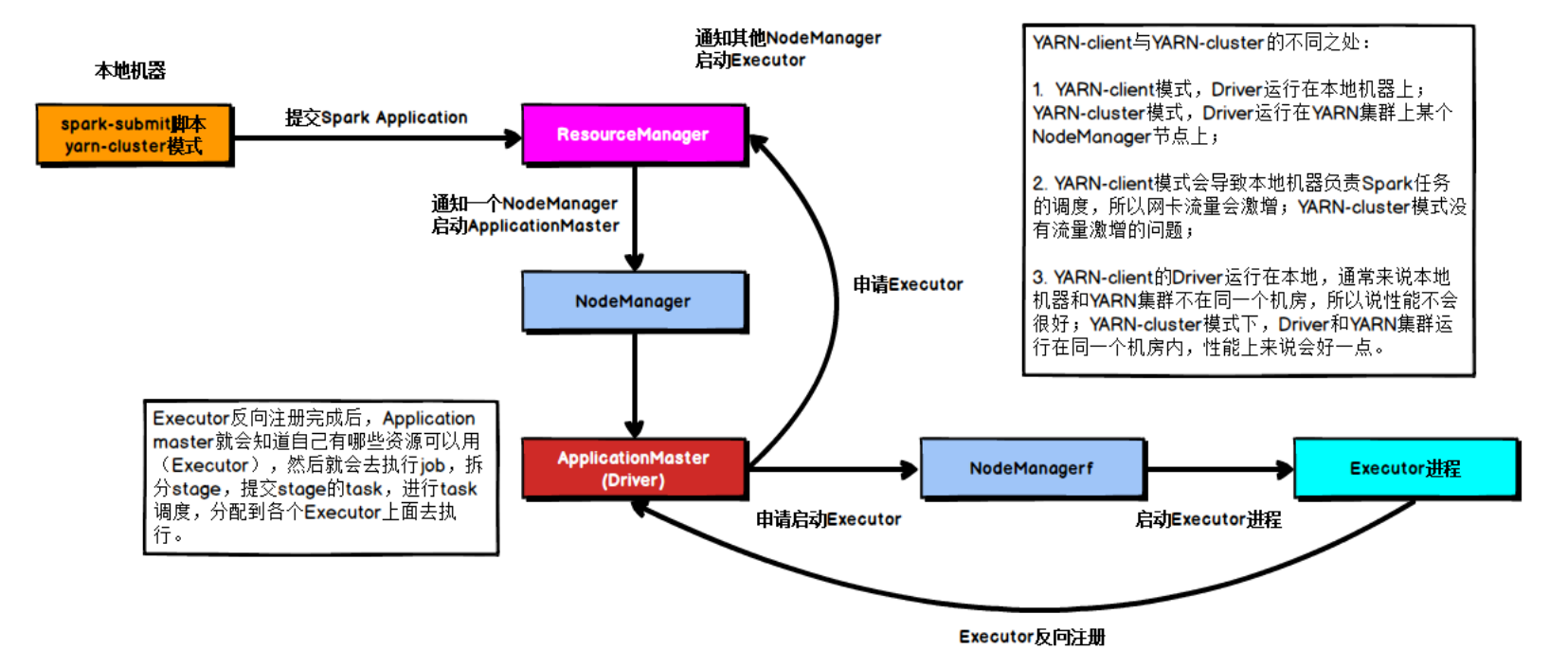
具体流程步骤如下:
1)、任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
3)、Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册;
5)、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行