1 共享变量
1.1 广播变量
# coding:utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
stu_info_list = [(1, '张大仙', 11),
(2, '王晓晓', 13),
(3, '张甜甜', 11),
(4, '王大力', 11)]
# 1. 将本地Python List对象标记为广播变量
broadcast = sc.broadcast(stu_info_list)
score_info_rdd = sc.parallelize([
(1, '语文', 99),
(2, '数学', 99),
(3, '英语', 99),
(4, '编程', 99),
(1, '语文', 99),
(2, '编程', 99),
(3, '语文', 99),
(4, '英语', 99),
(1, '语文', 99),
(3, '英语', 99),
(2, '编程', 99)
])
def map_func(data):
id = data[0]
name = ""
# 匹配本地list和分布式rdd中的学生ID 匹配成功后 即可获得当前学生的姓名
# 2. 在使用到本地集合对象的地方, 从广播变量中取出来用即可
for stu_info in broadcast.value:
stu_id = stu_info[0]
if id == stu_id:
name = stu_info[1]
return (name, data[1], data[2])
print(score_info_rdd.map(map_func).collect())
"""
场景: 本地集合对象 和 分布式集合对象(RDD) 进行关联的时候
需要将本地集合对象 封装为广播变量
可以节省:
1. 网络IO的次数
2. Executor的内存占用
"""在上述代码中,本地List对象和分布式RDD对象有了关联,RDD的每个分区在需要用到本地list对象时会向Driver申请,Driver会将list对象序列化后通过网络传输给各个线程。然而有的线程是在同一个Executor分区中的,这就造成了存储资源的浪费。
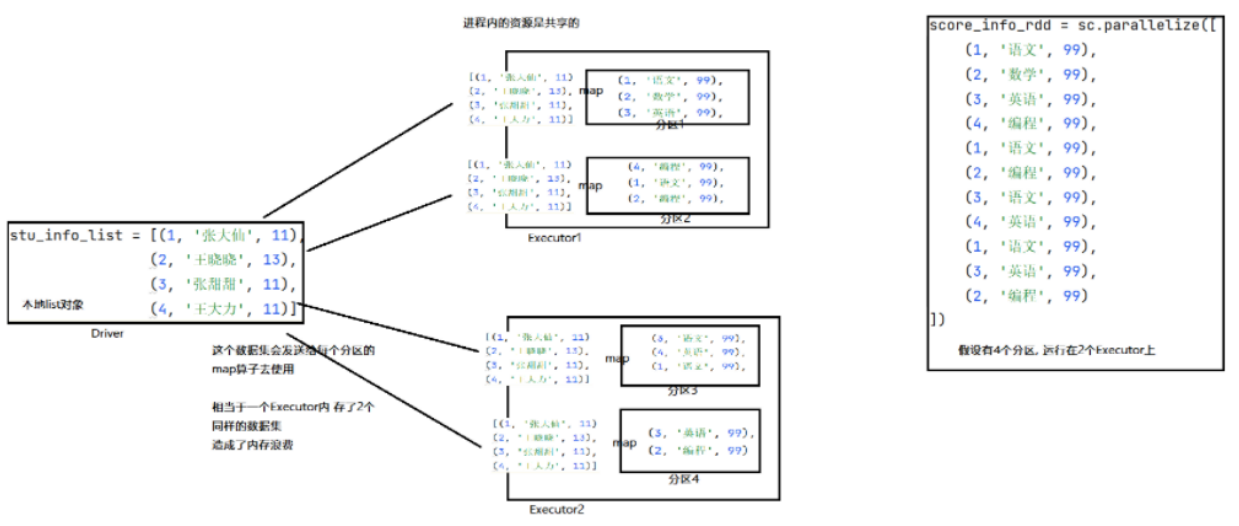
如果将本地list对象标记为广播变量对象,那么当上述场景出现的时候,Spark再接受到线程申请获取数据时,会先判断一下是否给过与该申请线程同一个Executor的其他线程这个本地List对象,即:
给每个Excutor来一份数据,而不是像原本那样,每一个分区的处理线程都来一份
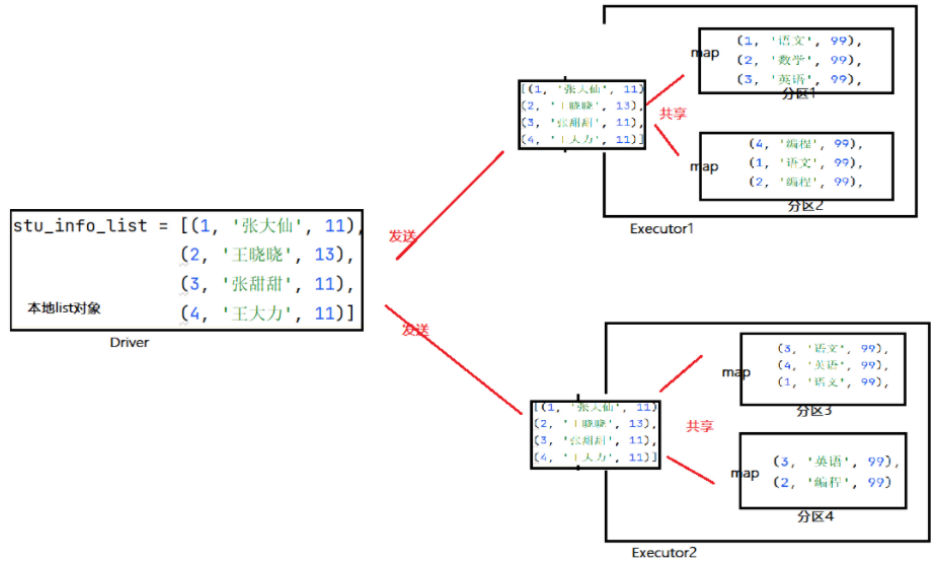
# 1.将本地list标记成广播变量即可
broadcast = sc.broadcast(stu_info_list)
# 2.使用广播变量,从broadcast对象中取出本地list对象即可
value = broadcast.value
# 也就是先放进去broadcast内部,然后从broadcast内部再取出来用,中间传输的时broadcast这个对象了,
# 只要中间传输的是broadcast对象,spark就会留意,只会给每个Executor发一份了1.2 累加器
# coding:utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 2)
count = 0
def map_func(data):
global count
count += 1
print(count)
rdd.map(map_func)
print(count)
# 代码中的count最后打印结果是0代码的问题在于:
count来自Driver对象,挡在分布式的map算子中需要count对象的时候,driver会将count对象发送给每一个executor一份(复制发送),每个executor各自收到一个,在最后执行print(count)的时候,这个被打印的count依旧是driver的那个,所以不管executor中累加到多少,都和driver这个count无关。
解决方案就是引入accumulator累加器
sc.accumulator(初始值)
# 这个对象唯一个前面提到的count不同的是,这个对象可以从各个executor中收集它们的执行结果,作用回自己身上。不过有一点仍需注意,前面缓存机制时说过,RDD是过程数据,执行完之后就被清除了,当想要再次调用时只能依据RDD血缘关系重新计算,这就会造成累加器被重复加了好几次。
2 Spark 内核调度
2.1 DAG
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
以 WordCount 程序为例,DAG图:
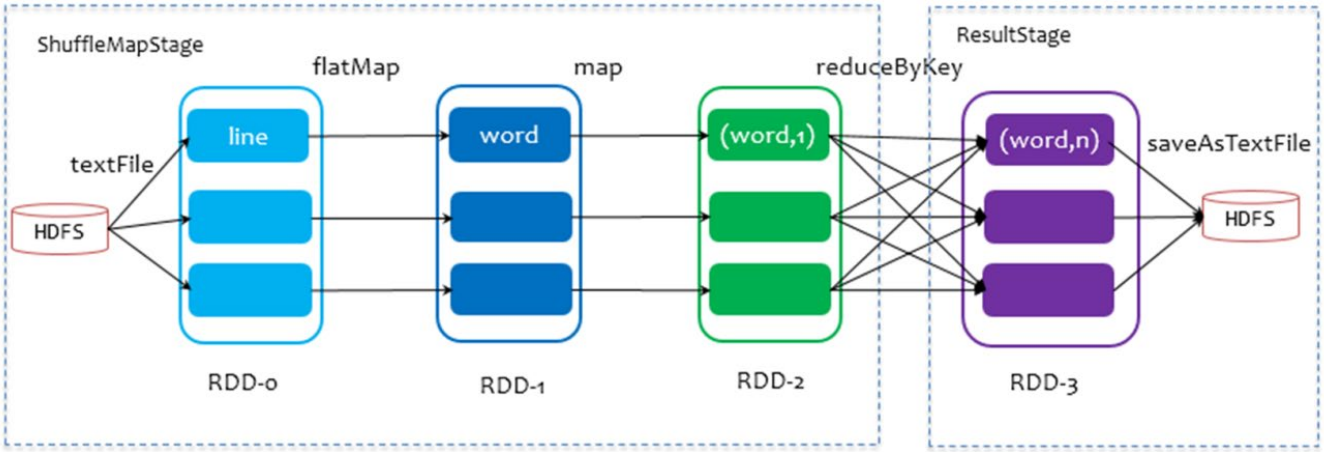
2.1.1 DAG定义
DAG是一个有向无环图,表示有方向没有形成闭环的一个执行流程图,用来表示代码的逻辑执行流程。
2.1.2 Job、Action与Application
Action:返回值不是RDD的算子
它的作用是一个触发开关,会将action算子之前的一串rdd依赖链条执行起来。
一个Action会将其前面一串的RDD依赖关系(Transformation)执行,也就是一个Action会产生一个DGA图。
一个Action产生的一个DAG,会在程序运行中产生一个JOB,所以1个ACTION = 1个DAG = 1个JOB
如果一个代码中,写了三个Action,那么这个代码运行起来会产生三个JOB,每个JOB有自己的DAG,一个代码运行起来,在Spark中称之为Application
层级关系:
1个Application中,可以有多个JOB,每一个JOB内含一个DAG,同时每一个JPB都是由一个Action产生的。
2.1.3 DAG和分区
DAG是Spark代码的逻辑执行图,这个DAG的最终是为了构建物理上的Spark详细执行计划而生,所以由于Spark是分布式(多分区)的,那么DAG和分区之间也是有关联的。
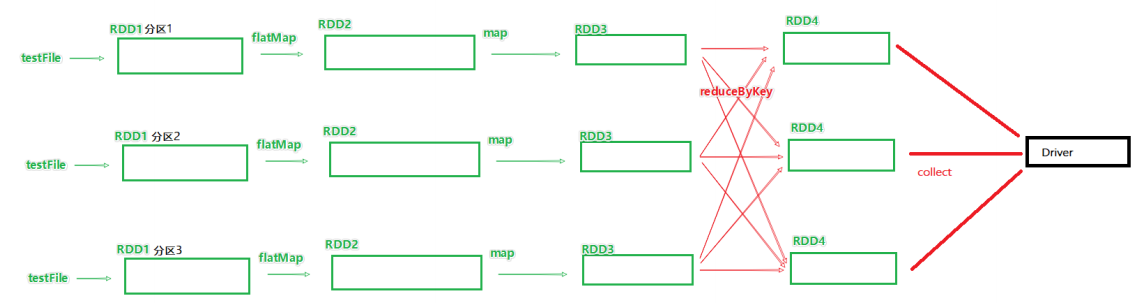
如图就得到了带有分区关系的DAG图。
2.2 DAG的宽窄依赖和阶段划分
2.2.1 宽窄依赖
在SparkRDD前后之间的关系,分为:
- 窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区
- 宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区
宽依赖还有一个别名:shuffle
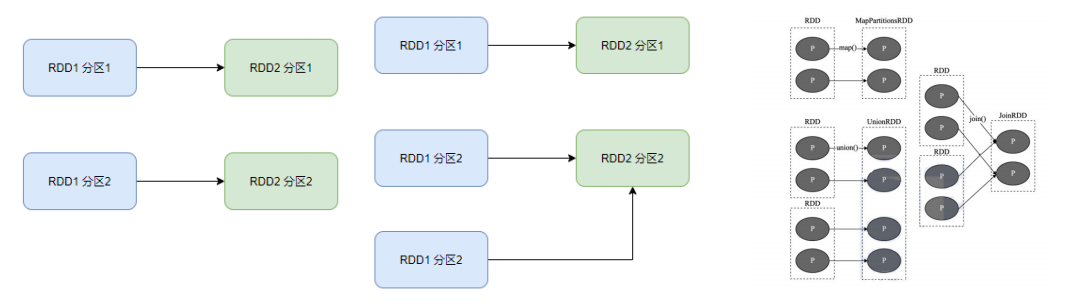
窄依赖中父RDD的一个分区数据只发给了一个子RDD的一个分区。
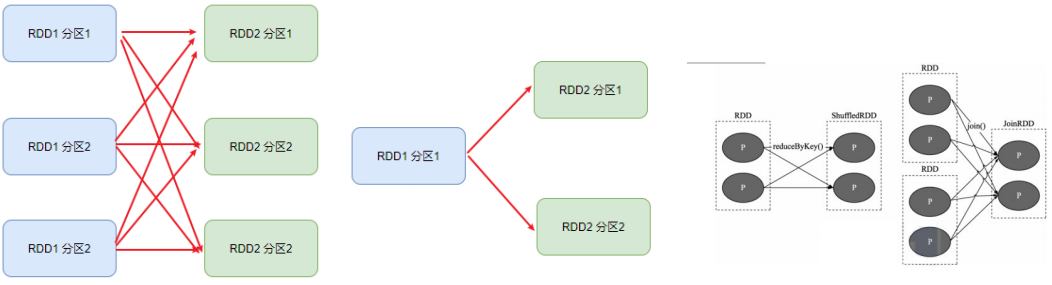
窄依赖中父RDD的一个分区数据发给了多个子RDD的一个分区。
2.2.2 阶段划分
对于Spark来说,会根据DAG,按照宽依赖,划分不同的DAG阶段。
划分依据:从后向前,遇到宽依赖就划分出一个阶段,称之为stage。
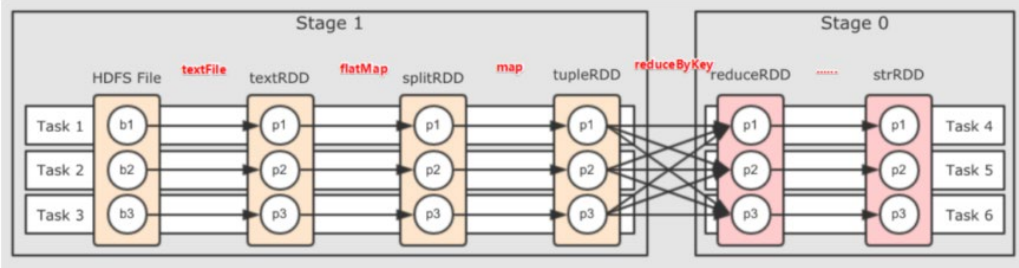
如图可以看到在DAG中,基于宽依赖,将DAG划分成了2个stage,在stage内部,一定都是窄依赖。
2.3 内存迭代运算
如上一章节最后一张图,基于带有分区的DAG以及阶段划分。可以从图中得到逻辑上最优的task分配,一个task是一个线程来具体执行。那么task1中rdd1、rdd2、rdd3的迭代计算,都是有一个task(线程完成),这一阶段的这一条线,是纯内存计算;task1、task2、task3,就形成了三个并行的内存计算管道。
Spark默认收到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数,如果全局并行度是3,其中大部分算子分区都是3。
注意:Spark我们一般推荐只设置全局并行度,不要在算子上设置并行度
2.4 并行度
2.4.1 并行度的设置
spark的并行:在同一时间内,有多少个task在同时运行,有多少个并行度,就被规划成多少个分区。
可以在代码中和配置文件中以及提交客户端的参数中设置,优先级从高到低为:
- 代码中
- 客户端提交参数中
- 配置文件中
- 默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量来作为默认并行度)
-- 全局并行度
-- 配置文件中:
-- conf/spark-defaults.conf中设置
spark.default.parallelism 100
-- 在客户端提交参数中:
bin/spark-submit --conf "spark.default.parallelism=100"
-- 在代码中设置
conf = SaprkConf()
conf.set("spark.default.parallelism","100")-- 针对RDD的并行度设置-不推荐
-- 只能在代码中写,算子:
repartition算子
coalesce算子
partitionBy算子2.4.2 并行度的规划
应设置并行度为CPU总核心的2~10倍
确保是CPU核心的整数倍即可,最小是2倍,最大一般十倍或更高(适量)即可
CPU的一个核心同一时间只能干一件事情,所以在100核心的情况下,设置100个并行,就能让CPU100%出力,但是如果task的压力不均衡,某个task先执行完了,就导致某个CPU空闲。所以我们将Task(并行)分配的数量变多,比如800个并行同一时间只有100个在运行,700个等待,但可以确保某个task运行完后有task补上,不让CPU闲下来,最大程度利用集群的资源。
2.5 任务调度
2.5.1 Sprak任务调度工作
Spark的任务,由Driver进行调度,这个工作包含:
- 逻辑DAG产生
- 分区DAG产生
- Task划分
- 将Task分配给Executor并监控其工作
如图,Spark程序的调度流程如图:
- driver被构建出来
- 构建SparkContext(执行环境入口对象)
- 基于DAG Schedule(DAG调度器)构建逻辑Task分配
- 基于TaskScheduler(Task调度器)讲逻辑Task分配到各个Executor上干活,并监控它们
- Worker(Executor),被TaskSchedule管理监控,听从他们的指令干活,并定期汇报进度
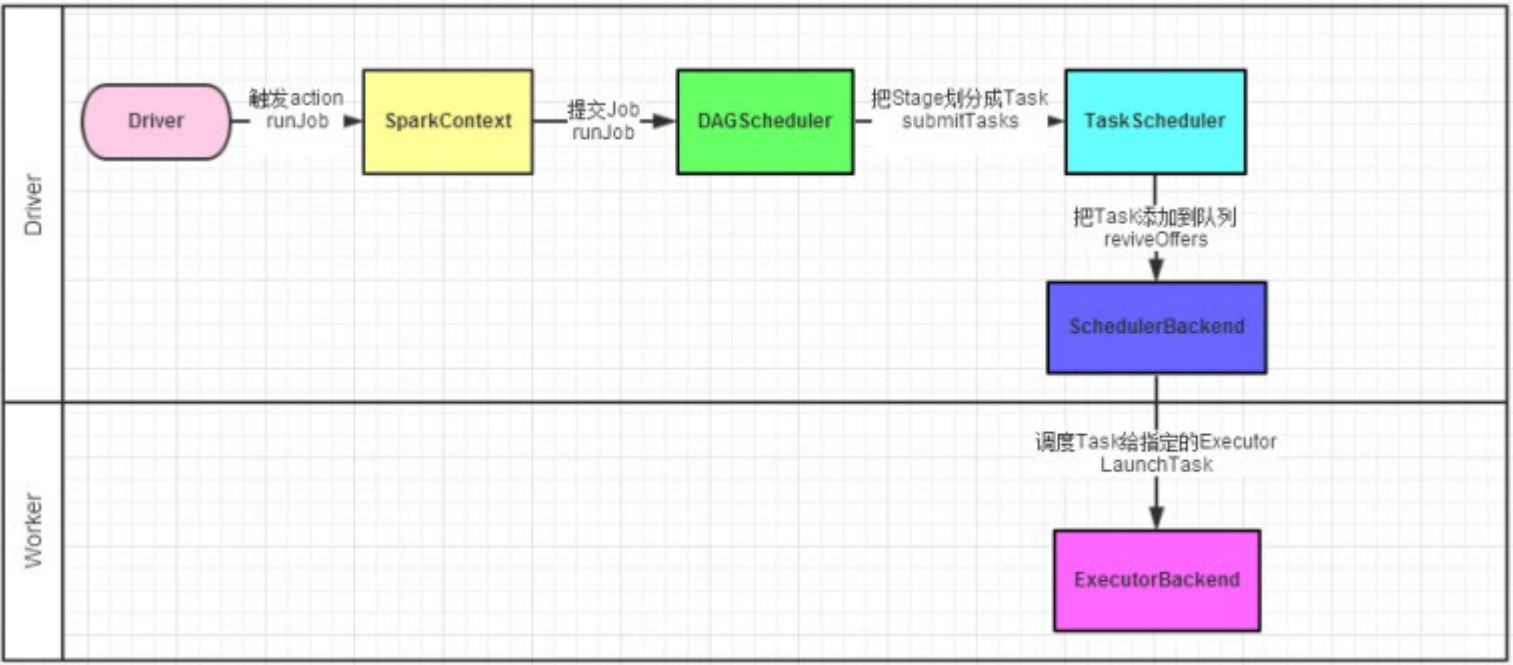
2.5.2 Driver内的两个组件
DAG调度器:
将逻辑的DAG图进行处理,最终得到逻辑上的Task划分。
Task调度器:
基于DAG Scheduler的产出,来规划这些逻辑的task,应该在那些无聊的executor上运行,以及监控管理他们的运行。