1 为什么需要RDD
分布式计算需要:
- 分区控制
- Shuffle控制
- 数据存储\序列化\发送
- 数据计算API
- 等一系列功能
这些功能, 不能简单的通过Python内置的本地集合对象(如 List\ 字典等)去完成。我们在分布式框架中, 需要有一个统一的数据抽象对象, 来实现上述分布式计算所需功能。这个抽象对象, 就是RDD。
2 什么是RDD
在Spark开山之作Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing这篇paper中,Matei等人提出了RDD这种数据结构。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
- Dataset:一个数据集合,用于存放数据的。
- Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
- Resilient:RDD中的数据可以存储在内存中或者磁盘中。
- RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
- 所有的运算以及操作都建立在 RDD 数据结构的基础之上。
- 可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract Class和泛型Generic Type

3 RDD的五大特性
RDD 数据结构内部有五个特性,前三个特征每个RDD都具备的,后两个特征可选的。
- RDD是有分区的
- 计算方法都会作用到每一个分片(分区)之上
- RDD之间是有互相依赖的关系的
- KV型RDD可以有分区器
- RDD分区数据的读取会靠近数据所在地
3.1 RDD是有分区的
RDD的分区是RDD数据存储的最小单位,一份RDD的数据,本质上是分隔成了多个分区。
>>> sc.parallelize([1,2,3,4,5,6,7,8,9], 3).glom().collect()
[[1,2,3],[4,5,6],[7,8,9]]
>>> sc.parallelize([1,2,3,4,5,6,7,8,9], 6).glom().collect()
[[1],[2,3],[4],[5,6],[7],[8,9]]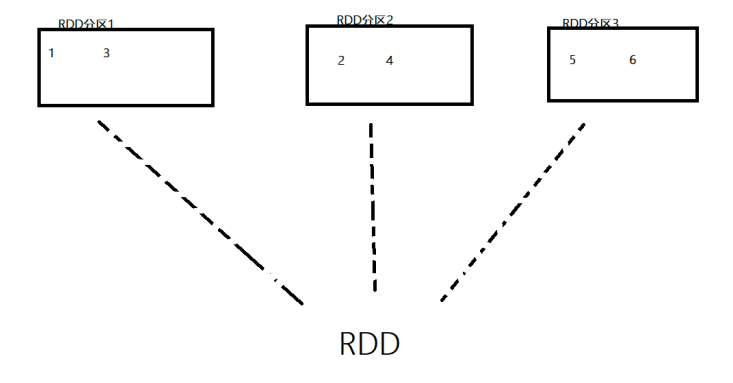
3.2 RDD的方法会作用在其所有的分区上
>>> sc.parallelize([1,2,3,4,5,6,7,8,9], 3).glom().collect()
[[1,2,3],[4,5,6],[7,8,9]]
>>> sc.parallelize([1,2,3,4,5,6,7,8,9], 3).map(lambda x: x*10).glom().collect()
[[10,20,30],[40,50,60],[70,80,90]]如上述代码,RDD有三个分区,在执行了map操作将数据都乘以十后,可以看到,三个分区的数据都乘以十了,说明.map是作用在了每一个分区之上。
3.3 RDD之间是有依赖关系的(RDD有血缘关系)
sc = SparkContext(conf = conf)
rdd1 = sc.textFile("../t.txt")
rdd2 = rdd1.flatMap(lambda x:x.split())
rdd3 = rdd2.map(lambda x:(x,1))
rdd4 = rdd3.reduceByKey(lambda a,b:a+b)
print(rdd4.collect())如上代码,RDD之间是有依赖的。如RDD2会产生RDD3,但是RDD2依赖于RDD1;同样,RDD3会产生RDD4,但RDD3依赖于RDD2;……;会形成一个依赖链条,这个链条称之为RDD的血缘关系。
3.4 Key-Value型的RDD可以有分区器
默认分区器:默认为Hash分区规则,也可以手动设置一个分区器( rdd.partitionBy 的方法来设置)
Key-Value RDD:RDD中存储的是二元元组,这就是Key-Value型,如("Hadoop", 3)
这个特征不是所有RDD都拥有的,因为不是所有的RDD都是Key-Value型数据。
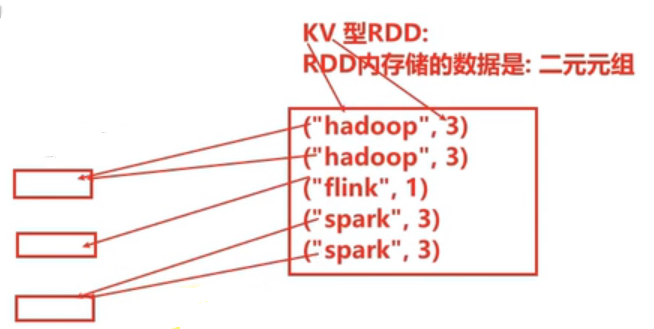
如上图所示,若存在以上五组数据,且设置三个分区,则遵从默认的Hash分区规则,Key相同的数据会被分至同一个区。
3.5 RDD分区数据的读取会靠近数据所在地
在初始RDD(读取数据的时候)规划时,分区会尽量规划到存储数据所在的服务器,因为这样可以走本地读取,避免网络读取所带来的时间损耗。
总之,Spark会在确保并行计算能力的前提下,尽量确保本地读取。
4 RDD编程入门
4.1 程序执行入口 :SparkContext对象
Spark RDD 编程的程序入口对象是SparkContext对象(不论何种编程语言),只有构建出SparkContext, 基于它才能执行后续的API调用和计算,本质上, SparkContext对编程来说, 主要功能就是创建第一个RDD出来。

from pyspark import SparkConf, SparkContext
if __name__ == "__main__":
# 构建SparkConf对象
conf = SparkConf().setAppName('helloworld').setMaster('local[*]')
# 构建SparkContext执行环境入口对象
sc = SparkContext(conf = conf)4.2 RDD的创建
RDD的创建主要有2种方式:
- 通过并行化集合创建 ( 本地对象 转 分布式RDD )
- 读取外部数据源 ( 读取文件 )
4.2.1 并行化创建:parallelize
使用parallelize API并行化创建是指将本地集合 -> 分布式RDD。这一步是分布式的开端(本地转分布式)
# 参数1:集合对象,如list等
# 参数2:分区数
rdd = sparkcontext.parallelize([1,2,3,4,5,6,7], 3)collect方法是将RDD(分布式对象)中每个分区的数据,都发送到Driver中,形成一个python List对象。
collect实现将RDD分布式 -> 本地集合
4.2.2 读取文件创建:textFile
使用textFile API可以读取本地数据,也可以读取hdfs数据
# 参数1:必填,文件路径,支持本地文件或HDFS文件,也支持一些其他协议如亚马逊的S3协议(路径为文件夹则将文件夹内所有文件都读取出来)
# 参数2:可选,表示最小分区数量
# 注意,参数2话语权不足,Spark有自己的判断,在它允许的范围内,参数2有效果,超过Spark允许的范围,参数2失效
sparkcontext.textFile(参数1, 参数2)4.2.3 一堆小文件的读取:wholeTextFiles
使用wholeTextFiles API,适合读取一堆小文件
# 参数1:必填,文件路径,支持本地文件或HDFS文件,也支持一些其他协议如亚马逊的S3协议(路径为文件夹则将文件夹内所有文件都读取出来)
# 参数2:可选,表示最小分区数量
# 注意,参数2话语权不足,分区数最多只能开到文件数量
sparkcontext.wholeTextFiles(参数1, 参数2)这个API偏向于少量分区读取数据,因为此API表明了自己是小文件读取专用,那么文件的数据很小、分区很多,导致shuffle的几率更高。所以尽量少分区读取数据。
4.2.4 获取分区数量:getNumPartitions
getNumPartitions API获取分区数量,返回值是int数字
>>> rdd.getNumPartitions()
34.3 RDD算子的概念与分类
算子:分布式集合对象上的API称之为算子
方法\函数:本地对象的API,叫做方法\函数
RDD的算子分为两类:
- Transformation:转换算子
- Action:动作(行动)算子
Transformation算子
- 定义:RDD的算子,返回值仍旧是一个RDD的,称之为转换算子
特性:这类算子是lazy(懒加载)的,如果没有action算子,Transformation算子是不工作的。
Action算子
- 定义:返回值不是RDD的就是action算子。
对于这两类算子来说,Transformation算子相当于在构建执行计划,action是让这个执行计划开始工作的指令。
如果没有action,transformation算子之间的迭代关系就是一个没有通电的流水线。只有action到来,这个数据处理的流水线才开始工作。
4.4 RDD常用的转换算子
4.4.1 map算子
功能:将RDD的数据一条条处理(处理的逻辑基于map算子中接收的处理函数),返回新的RDD。
# func: f:(T) -> U
rdd.map(func)4.4.2 flatMap算子
功能:对RDD执行map操作,然后进行解除嵌套操作(展平,即多维变一维)
# 解除嵌套
# 嵌套的list
l = [[1,2,3], [4,5,6], [7,8,9]]
# 接触嵌套后:
l = [1,2,3,4,5,6,7,8,9]>>> rdd = sc.parallelize(["hadoop hive spark", "hadoop hadoop flink", "spark hadoop hive"])
>>> rdd1 = rdd.map(lambda x: x.split())
>>> rdd1.collect()
[['hadoop','hive','spark'], ['hadoop','hadoop','flink'], ['spark','hadoop','hive']]
>>> rdd2 = rdd.flatMap(lambda x: x.split())
>>> rdd2.collect()
['hadoop','hive','spark','hadoop','hadoop','flink','spark','hadoop','hive']4.4.3 reduceByKey算子
功能:针对KV型RDD,自动按照key分组,然后根据所提供的聚合逻辑,完成组内数据(value)的聚合操作。(按key分组,按value聚合)
# func:(V,V) -> V
# 接受两个传入参数(类型需一致),返回一个返回值,类型和传入要求一致。
rdd.reduceByKey(func)reduceByKey中的聚合逻辑(以[1,2,3,4,5],lambda a,b:a+b为例):
>>> rdd = sc.aprallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])
>>> result = rdd.reduceByKey(lambda a,b: a+b)
>>> print(result.collect())
[('b',3),('a',2)]reduceByKey中接收的函数,只负责聚合,不理会分组
分组时自动by key来分组的
4.4.4 mapValues算子
功能:针对二元元组RDD,对其内部的二元元组的Value执行map操作。
# func: (V) -> U
# 注意传入的参数是二元元组的value值
# 这个算子支队value处理
rdd.mapValues(func)>>> rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])
>>> print(rdd.mapValues(lambda x:x*10).collect())
[('a', 10), ('a', 10), ('b', 10), ('b', 10), ('b', 10)]4.4.5 groupBy算子
功能:将rdd的数据进行分组
rdd.groupBy(func)
# func (T) -> K
# 函数要求传入一个参数,返回一个返回值,类型无所谓
# 这个算子是拿到参数函数的返回值后,将所有相同返回值的放入一个组中
# 分组完成后,每一个数据都是一个二元元组,key就是返回值,所有同组的数据放入一个迭代器对象中作为value>>> rdd = sc.parallelize([1,2,3,4,5])
>>> rdd1 = rdd.groupBy(lambda num: 'even' if num%2==0 else 'odd')
>>> print(rdd1.map(lambda x:(x[0], list(x[1]))).collect())
[('even',[2,4]),('odd',[1,3,5])]4.4.6 Filter算子
功能:过滤想要的数据进行保留
rdd.filter(func)
# func: (T) -> bool,传入一个任意类型的参数进来,返回一个bool类型>>> rdd = sc.parallelize([1,2,3,4,5,6])
>>> print(rdd.filter(lambda x:x%2==1).collect())
[1, 3, 5]4.4.7 distinct算子
功能:对RDD数据进行去重,返回新的RDD
rdd.distinct(参数1)
# 参数1:驱虫分区数量,一般不用传>>> rdd = sc.parallelize([1,1,1,2,2,5,5,5,5,6,6,6,6])
>>> rdd.distinct().collect()
[1, 5, 2, 6]
>>> rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])
>>> rdd.distinct().collect()
[('a', 1), ('b', 1)]4.4.8 union算子
功能:2个rdd合并成1个rdd返回(只合并,不去重,不同类型RDD依旧可以混合)
rdd.union(other_rdd)>>> rdd1 = sc.parallelize([1,1,2,2])
>>> rdd2 = sc.parallelize([1,1,2,2,3,3,4,4])
>>> union_rdd = rdd1.union(rdd2)
>>> union_rdd.collect()
[1, 1, 2, 2, 1, 1, 2, 2, 3, 3, 4, 4]4.4.9 join算子
功能:对两个RDD执行JOIN操作(可实现SQL的内\外连接)(只能用于二元元组)
rdd.join(other_rdd) # 内连接
rdd.leftOuterJoin(other_rdd) # 左外连接
rdd.rightOuterJoin(other_rdd) # 右外连接>>> x = sc.parallelize([(1001,'zhangsan'), (1002,'lisi'), (1003,'wangwu'), (1004, 'maliu')])
>>> y = sc.parallelize([(1001,'sales'), (1002,'tech')])
>>> print(x.join(y).collect())
[(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))]
>>> print(x.leftOuterJoin(y).collect())
[(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech')), (1003, ('wangwu', None)), (1004, ('maliu', None))]4.4.10 intersection算子
功能:求2个rdd的交集,返回一个新rdd
rdd.intersection(other_rdd)>>> rdd = sc.parallelize([1,3,5,7])
>>> rdd1 = sc.parallelize([1,3,8,9])
>>> rdd.intersection(rdd1).collect()
[1, 3] 4.4.11 glom算子
功能:将RDD的数据加上嵌套,这个嵌套按照分区来进行
# 无需参数
rdd.glom()>>> rdd = sc.parallelize([1,2,3,4,5,6,7,8,9], 3)
>>> rdd.glom().collect()
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]4.4.12 groupByKey算子
功能:针对KV型RDD,自动按照key分组
# 无需参数
rdd.groupByKey()>>> rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])
>>> rdd.groupByKey().collect()
[('b', <pyspark.resultiterable.ResultIterable object at 0x7f4b817541d0>), ('a', <pyspark.resultiterable.ResultIterable object at 0x7f4b817540d0>)]
>>> rdd.groupByKey().map(lambda x:list(x[1])).collect()
[[1, 1, 1], [1, 1]]
>>> rdd.groupByKey().map(lambda x:(x[0],list(x[1]))).collect()
[('b', [1, 1, 1]), ('a', [1, 1])]4.4.13 sortBy算子
功能:基于指定的排序依据对RDD数据进行排序。
rdd.sortBy(func, ascending=False, numPartitions=1)
# func: (T) -> U: 告知按照rdd中的哪个数据进行排序,比如lambda x:x[1] 表示rdd中的第二列元素进行排序
# ascending True升序,False降序
# numPartitions:用多少分区排序>>> rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,1,2,3,4,5,6,7,8,9,1,2,3,4,5,6,7,8,9])
>>> rdd.sortBy(lambda x:x).collect()
[1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6, 7, 7, 7, 8, 8, 8, 9, 9, 9]
>>> rdd = sc.parallelize([('a', 1), ('a', 3), ('b', 8), ('b', 3), ('b', 1)])
>>> rdd.sortBy(lambda x:x[1]).collect()
[('a', 1), ('b', 1), ('a', 3), ('b', 3), ('b', 8)]
>>> rdd.sortBy(lambda x:(x[0],x[1])).collect()
[('a', 1), ('a', 3), ('b', 1), ('b', 3), ('b', 8)]4.4.14 sortByKey算子
功能:针对KV型RDD,按照key进行排序
sortByKey(ascending=True, numPartitions=None, keyfunc=<function RDD.<lambda>>)
# ascending: 升序or降序,True升,False降,默认升
# numPartitions: 按照几个分区进行排序,如果全局有序,设置为1
# keyfunc: 在排序前对key进行处理,语法是(K) -> U,一个参数传入,返回一个值>>> rdd = sc.parallelize([('a', 1), ('E', 1), ('C', 1), ('D', 1), ('b', 1), ('g', 1), ('f', 1),
('y', 1), ('u', 1), ('i', 1), ('o', 1), ('p', 1),
('m', 1), ('n', 1), ('j', 1), ('k', 1), ('l', 1)], 3)
>>> print(rdd.sortByKey(ascending=True, numPartitions=1).collect())
[('C', 1), ('D', 1), ('E', 1), ('a', 1), ('b', 1), ('f', 1), ('g', 1), ('i', 1), ('j', 1), ('k', 1), ('l', 1), ('m', 1), ('n', 1), ('o', 1), ('p', 1), ('u', 1), ('y', 1)]
>>> print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())
[('a', 1), ('b', 1), ('C', 1), ('D', 1), ('E', 1), ('f', 1), ('g', 1), ('i', 1), ('j', 1), ('k', 1), ('l', 1), ('m', 1), ('n', 1), ('o', 1), ('p', 1), ('u', 1), ('y', 1)]keyfunc并不会改变数据的值,只会改变排序时依据的值,如上,虽然lower()变小写了,但是输出时仍是大写。
4.5 常用动作算子
4.5.1 countByKey算子
功能:一般适用于KV型的RDD,用于统计key出现的次数
>>> rdd = sc.parallelize(['hadoop','spark','hadoop'])
>>> rdd1 = rdd.map(lambda x:(x,1))
>>> result = rdd1.countByKey()
>>> print(result)
defaultdict(<class 'int'>, {'hadoop': 2, 'spark': 1})
>>> type(result)
<class 'collections.defaultdict'>注意:countByKey操作后的result已经不是一个RDD了。
4.5.2 collect算子
功能:将RDD各个分区内的数据统一收集到Driver中,形成一个List对象
rdd.collect()这个算子是将RDD各个分区数据都拉取到Driver中,需要注意的是,RDD是分布式对象,其数据量可以很大,所以用这个算子前要确保结果数据及不会太大,防止把Driver内存撑爆。
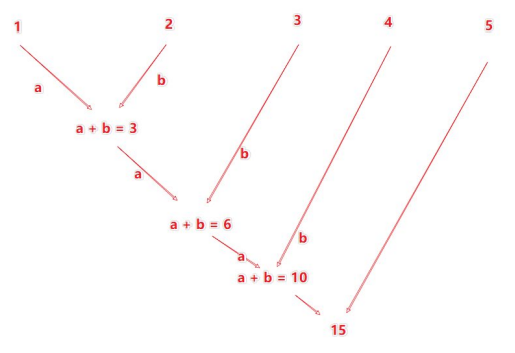
### 4.5.3 reduce算子
功能:对RDD数据集按照所传入的逻辑进行聚合
rdd.reduce(func)
# func: (T, T) -> T
# 两个参数传入,一个返回值,返回值和参数要求类型一致reduce算子执行流程:
>>> rdd = sc.parallelize(range(10))
>>> print(rdd.reduce(lambda a,b:a+b))
454.5.6 fold算子
功能:和reduce一样,接受传入逻辑进行聚合,聚合是带有初始值的。这个初始值会作用在分区内聚合和分区间聚合时。
如:[[1,2,3], [4,5,6], [7,8,9]]
数据分布在三个分区
分区1:123聚合的时候带上10作为初始值得到16
分区1:456聚合的时候带上10作为初始值得到25
分区1:789聚合的时候带上10作为初始值得到34
rdd.fold(参数, func)
# 参数:分区内及分区间聚合时带有的初始值
# func:func: (T, T) -> T>>> rdd = sc.parallelize(range(1,10),3)
>>> print(rdd.fold(10, lambda a,b: a+b))
85有3次分区内聚合,一次分区间聚合,因此额外多了40
4..5.5 first算子
功能:取RDD的第一个元素。
>>> rdd = sc.parallelize(range(1,10),2)
>>> rdd.collect()
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> rdd.glom().collect()
[[1, 2, 3, 4], [5, 6, 7, 8, 9]]
>>> rdd.first()
14.5.7 take算子
功能:取RDD中的前n个元素,组合成List返回。
>>> rdd = sc.parallelize(range(1,10),2)
>>> rdd.collect()
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> rdd.glom().collect()
[[1, 2, 3, 4], [5, 6, 7, 8, 9]]
>>> rdd.take(5)
[1, 2, 3, 4, 5]4.5.8 top算子
功能:对RDD数据集进行降序排序,取前n个,组合成List返回
>>> rdd = sc.parallelize([1,5,3,9,5,2,3,0,1,2,9,4,5,3])
>>> rdd.top(5)
[9, 9, 5, 5, 5]4.5.9 count算子
功能:计算RDD有多少条数据,返回值是一个数字
>>> sc.parallelize([1,2,3,4]).count()
64.5.10 takeSample算子
功能:随机抽样RDD的数据
takeSample(参数1:True or False, 参数2:采样数, 参数3:随机数种子)
# 参数1:True表示运行去同一个数字,False表示不允许取同一个数字,和数据内容无关,重复指的是同一个位置上的数据
# 参数2:抽样要几个>>> rdd = sc.parallelize([1,5,3,9,5,2,3,0,1,2,9,4,5,3])
>>> rdd.takeSample(True, 5)
[3, 3, 1, 3, 2]
>>> rdd.takeSample(True, 20)
[3, 1, 5, 5, 3, 5, 2, 1, 3, 2, 1, 0, 5, 1, 3, 5, 2, 3, 9, 0]
>>> rdd.takeSample(False, 20)
[0, 3, 3, 1, 4, 1, 5, 3, 2, 5, 9, 5, 9, 2]4.5.11 takeOrdered算子
功能:对RDD进行排序取前N个
rdd.takeOrdered(参数1, 参数2)
# 参数1:要几个数据
# 参数2:堆排序的数据进行更改(不会更改数据本身,只是在排序时换个样子)>>> rdd = sc.parallelize([1,3,2,4,7,9,6],1)
>>> rdd.takeOrdered(3)
[1, 2, 3]
>>> rdd.takeOrdered(3,lambda x:-x)
[9, 7, 6]4.5.12 foreach算子
功能:对RDD的每一个元素,执行你提供的逻辑的操作(和map一个意思),但是这个算子没有返回值。
rdd.foreach(func)
# func: (T) -> None>>> rdd = sc.parallelize([1,2,3,4,5])
>>> r = rdd.foreach(lambda x:print(x*10))
40
50
10
30
20
>>> print(r)
Noneforeach中函数不能给返回值,所以直接在里面打印了。foreach不需要提交给Driver,直接在分区下运行完毕。(可以用来高效写入SQL、打印等操作)
4.5.13 saveAsTextFile算子
功能:将RDD的数据写入文本文件中,支持本地写出和HDFS等文件系统。
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
rdd.saveAsTextFile("hdfs://node1:8020/output/test")参数为文件夹路径,有几个分区产生多少个文件,且亦无需向Driver汇报
4.6 分区操作算子
4.6.1 mapPartitions算子
功能:一次传递一整个分区,然后按接收到的函数逻辑处理数据。
>>> rdd = sc.parallelize([1,2,3,4,5],2)
>>> rdd.glom().collect()
[[1, 2], [3, 4, 5]]
>>> rdd1 = rdd.mapPartitions(lambda x: [i*10 for i in x])
>>> rdd1.glom().collect()
[[10, 20], [30, 40, 50]]4.6.2 foreachPartition算子
功能:和普通的foreach一致,但一次处理的是一整个分区数据。
4.6.3 partitionBy算子
功能:对RDD进行自定义分区操作
rdd.partitionBy(参数1, 参数2)
# 参数1 重新分区后有几个分区
# 参数2 自定义分区规则,函数传入
# 参数2:(K) -> int 一个传入参数进来,类型无所谓,但是返回值一定是int类型,将key传给这个函数,根据所写函数逻辑返回一个分区编号,分区编号从0开始,不要超过分区数-1def partition_self(key):
if key[0] == 'h':
return 0
elif key[0] == 's':
return 1
else:
return 2
rdd = sc.parallelize()
>>> rdd = sc.parallelize(["hadoop hive spark", "hadoop hadoop flink", "spark hadoop hive"])
>>> rdd1 = rdd.flatMap(lambda x:x.split())
>>> rdd2 = rdd1.map(lambda x:(x,1))
>>> rdd2.collect()
[('hadoop', 1), ('hive', 1), ('spark', 1), ('hadoop', 1), ('hadoop', 1), ('flink', 1), ('spark', 1), ('hadoop', 1), ('hive', 1)]
>>> rdd2.partitionBy(3,partition_self).glom().collect()
[[('hadoop', 1), ('hive', 1), ('hadoop', 1), ('hadoop', 1), ('hadoop', 1), ('hive', 1)], [('spark', 1), ('spark', 1)], [('flink', 1)]]4.6.4 repartition算子
功能:对RDD的分区执行重新分区(仅数量)
rdd.repartition(N)
# 传入N决定新的分区数>>> rdd = sc.parallelize(range(10),2)
>>> rdd.glom().collect()
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
>>> rdd1 = rdd.repartition(5)
>>> rdd1.glom().collect()
[[], [0, 1, 2, 3, 4], [], [5, 6, 7, 8, 9], []]
>>> rdd2 = rdd1.repartition(1)
>>> rdd2.glom().collect()
[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]注意:对分区的数量进行操作,一定要慎重。
一般情况下,我们写Spark代码,除了要求全局排序设置为1个分区外,多数时候,所有API中关于分区相关的代码都不必太多例会。因为如果更改分区了,可能会影响并行计算(内存迭代的并行管道数量),且分区如果增加,极大可能导致shuffle。
4.6.5 coalesce算子
功能:修改分区数量
rdd.coalesce(num, shuffle=False)
# 相当于安全阀,shuffle必须为True才能增加分区数,而repatition就是调用的coalesce,且shuffle始终为True>>> rdd = sc.parallelize(range(10),3)
>>> rdd.glom().collect()
[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
>>> rdd.coalesce(2).glom().collect()
[[0, 1, 2], [3, 4, 5, 6, 7, 8, 9]]
>>> rdd.coalesce(4).glom().collect()
[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
>>> rdd.coalesce(4,shuffle=True).glom().collect()
[[6, 7, 8, 9], [3, 4, 5], [], [0, 1, 2]]4.7 groupByKey与reduceByKey的区别
在功能上:
- groupByKey仅仅有分组功能而已
- reduceBykey除了有ByKey的分组功能外,还有reduce聚合功能。
如果对数据执行分组+聚合,那么使用这两个算子的性能差别是很大的。
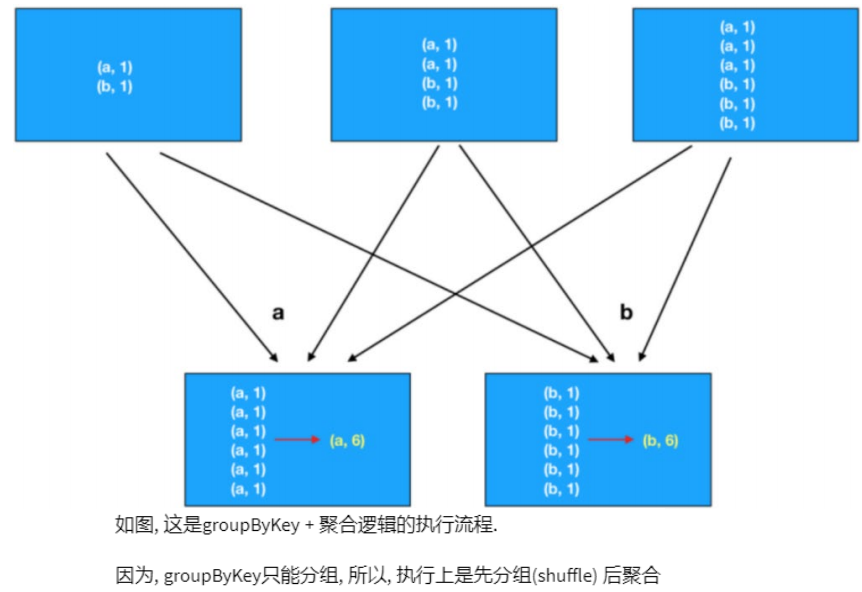
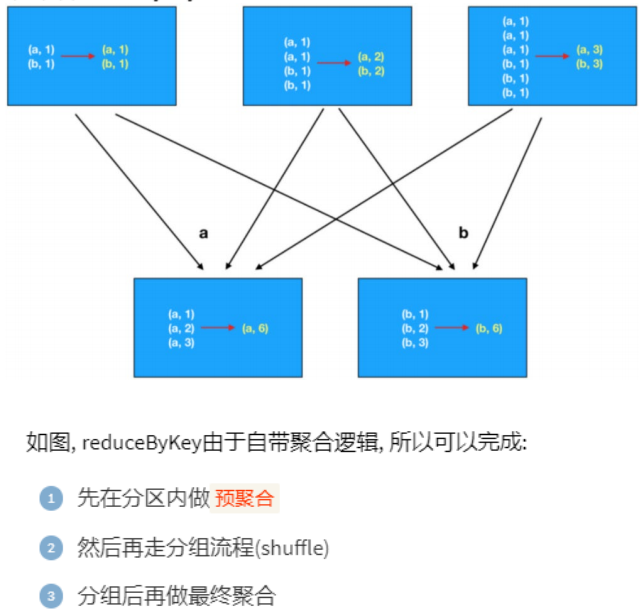
对于groupByKey,reduceByKey最大的提升在于,分组前进行了预聚合,那么再shuffle分组节点,被shuffle的数据可以极大地减少。这就极大的提升了性能。
分组+聚合,首选reduceByKey,数据越大,对groupByKey的优势就越高。
5 RDD的持久化
5.1 RDD的数据是过程数据
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失。RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了。
这个特性可以最大化的利用资源,老旧RDD没用了就从内存中清理,给后续的计算腾出内存空间。
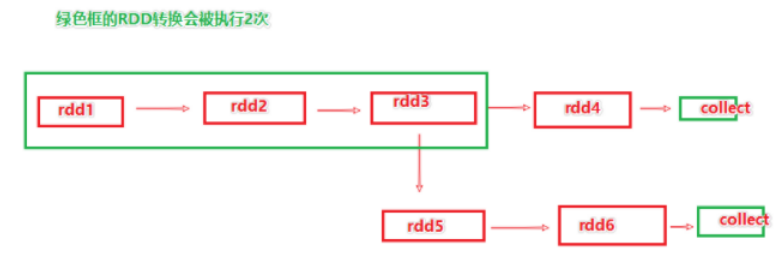
如上图,rdd3被两次使用,第一次使用之后,其实rdd3就不存在了。第二次用的时候,只能基于rdd的血缘关系,从rdd1重新执行,构建出来rdd3,供rdd5使用。
5.2 RDD的缓存
在上一章节,若rdd3不消失,那么rdd1->rdd2->rdd3这个链条就不会执行两次,或者更多次,因此上述场景一定要执行优化。
Spark提供了缓存API,可以让我们通过调用API,将指定的RDD数据保留在内存或磁盘上。
'''加入缓存的API'''
# 缓存到内存中
rdd.cache()
# 仅内存缓存
rdd.persist(StorageLevel.MEMORY_ONLY)
# 仅内存缓存,2个副本
rdd.persist(StorageLevel.MEMORY_ONLY_2)
# 仅缓存硬盘上
rdd.persist(StorageLevel.DISK_ONLY)
# 仅缓存硬盘上,2个副本
rdd.persist(StorageLevel.DISK_ONLY_2)
# 仅缓存硬盘上,3个副本
rdd.persist(StorageLevel.DISK_ONLY_3)
# 先放内存,不够放硬盘
rdd.persist(StorageLevel.MEMORY_AND_DISK)
# 先放内存,不够放硬盘,2个副本
rdd.persist(StorageLevel.MEMORY_AND_DISK_2)
# 堆外内存(系统内存)
rdd.persist(StorageLevel.OFF_HEAP)
# 一般建议使用rdd.persist(StorageLevel.MEMORY_AND_DISK)
# 如果集群内存较小,建议使用rdd.persist(StorageLevel.DISK_ONLY),或者用CheckPoint
'''主动清理缓存的API'''
rdd.unpersist()特点:
- 保留血缘关系
- 分散存储
5.3 RDD的CheckPoint
CheckPoint存储RDD数据是集中收集各个分区数据进行存储,而缓存是分散存储。
缓存和CheckPoint的对比:
- CheckPoint不管分区数量多少,风险是一样的, 缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行,HDFS是高可靠性存储,CheckPoint被认为是安全的
- CheckPoint不支持内存,缓存可以,缓存如果写内存,性能比CheckPoint要好一些
- CheckPoint应为设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全(只要跟内存存储有关一律认为不安全),所以保留。
# 设置CheckPoint第一件事:选择CP的保存路径
# 如果是Local模式,可以支持本地文件系统,如果在集群运行,千万要用HDFS
sc.setCheckPointDir("hdfs://node1:8020/output")
# 用的时候,直接调用CheckPoint算子即可
rdd.CheckPoint()